JIS, EUC, SJIS の 漢字コード
3つの 漢字コード
現在、コンピュータ上で日本語テキストを表現するのに用いられている漢字コードはおもに 3種類ある
(昔は区点コードというコード体系もあったが、今ではすたれてしまった)。
その 3種類は次のようなものである。なお、最初に「0x」がつく文字列は、それが 16進数
(Hexadecimal) 表記であることを表す。
- JIS 漢字コード
- ASCII コード 0x21 〜 0x7E の文字 2つを組み合わせて 1つの 漢字を表現する。
制御文字 (文字コード 0x1F 以下の文字)
と共有できる、7bit 転送でも表現できる などの利点があるものの、漢字と通常の ASCII コード文字 (single-byte のアルファベット) が
共存できない。
このために「漢字 IN」と「漢字 OUT」という 2つの 制御シーケンス (制御文字列) が導入されている。
- 漢字 IN … ESC $ B (0x1B, 0x24, 0x42)
- 漢字 OUT … ESC ( B (0x1B, 0x28, 0x42)
端末が漢字 IN を読むとそれ以降の文字はすべて JIS 漢字コードとして 解釈される。
漢字 OUT を読むと端末は通常の状態に戻り、来た文字を single-byte の文字として解釈する。
この方式には、もし何らかの 理由で漢字 IN/OUT を取りこぼした場合、 表示される文字が化けてしまうという大きな欠点がある。
これらの 制御シーケンスは、標準的な端末 (kterm など) では、ネストされる。
つまり、漢字 IN が 2度読まれると、端末は漢字 OUT が 2度くるまで もとの状態に戻らない。
その他の漢字 IN / 漢字 OUT
ときどき kterm を使って古いテキストファイルなどを見ていると、いきなり漢字などが小さく表示されることがある。
これは、 漢字 IN/漢字 OUT の制御シーケンスとして、(現在使われている 「新 JIS (JIS-1983)」以前の) いわゆる
「旧 JIS (JIS-1978) 漢字コード」で規定されたものを使っているために 起こるようだ。
具体的には以下のシーケンスが 漢字 IN/漢字 OUT に 使われていると起こる :
- 漢字 IN … ESC $ @ (0x1B, 0x24, 0x40)
- 漢字 OUT … ESC ( J (0x1B, 0x28, 0x4A)
- SHIFT-JIS 漢字コード
- JIS 漢字コードの欠点を改良し、漢字 IN/OUT を用いずに ASCII コード文字 および半角カナ文字と混在できるようにした
方式である。
「Microsoft Kanji」コードと呼ばれることもある。もちろん、制御文字とも混在できる。
この方式における 漢字の表示アルゴリズムは次のようになっている。
- 1バイト目が 0x00 〜 0x80、あるいは 0xA0 〜 0xDF に 入っていたらそれを single-byte の文字としてそのまま表示する。
0x20 〜 0x7F は ASCII コードに準じ、 0xA0 〜 0xDF には いわゆる半角カナ文字が割りあてられている。
- 1バイト目が 0x81 〜 0x9F、あるいは 0xE0 〜 0xFF に 入っていたら それは 漢字の 1バイト目とみなし、次の
1バイトと合わせて 漢字を表示する。
この方式の欠点は、文字を 8ビットで 表現しなければならないということ、途中の 1バイトを取りこぼしたら
あとの文字すべてが化けてしまう 危険性があることである。
また、この方式はパソコンではよく用いられて きたが、現在の UNIX ではあまり使われておらず、従って Internet で
テキストをやりとりする際にも まだ 対応が不十分である。UNIX では 後述する EUC 漢字コードがよく用いられている。
- EUC 漢字コード
- UNIX で漢字を表現するために用いられた方式である。
漢字 IN/OUT を 使わずに制御文字、ASCII コード文字と混在できるが、SHIFT-JIS 方式と 同じく
8ビット幅でないと表現できない、文字化けの危険性があるなどの 欠点がある。
表示アルゴリズムは SHIFT-JIS と似ており、次のように なっている。
- 1バイト目が 0x00 〜 0x7F だったら、それを single-byte 文字として そのまま表示する。
- 1バイト目が 0x8E だったら、そのあとに続く文字を 半角カナとして 表示する (このときの 2バイト目は SHIFT-JIS
における半角カナ文字を 表すコードと同じものが使われる)。
- 1バイト目が 0xA1 〜 0xFE だったら、それは漢字の 1バイト目とみなし、次の 1バイトと合わせて漢字を表示する。
それぞれの漢字コードの変換
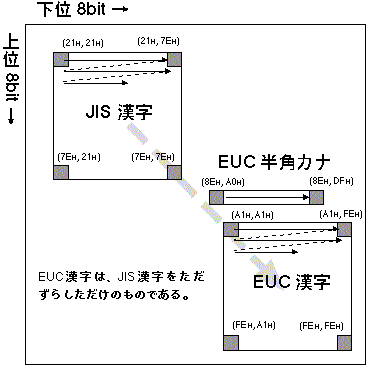
- JIS 漢字コード → EUC 漢字コード
- これら 2つの間のコード変換は単純である。
EUC 漢字コードは JIS 漢字コードの 2バイトのそれぞれの 第7ビット目を 1にしてある だけなので
(0x21 → 0xA1, 0x7E → 0xFE となる)、第7ビット目を 立てれば EUC になるし、おろせば JIS になるのである。
ただし例外は EUC で使われている半角カナ文字で、これを表現する手段は JIS にはない。
これら 2つのコードの関係を図にまとめると 次のようになる。
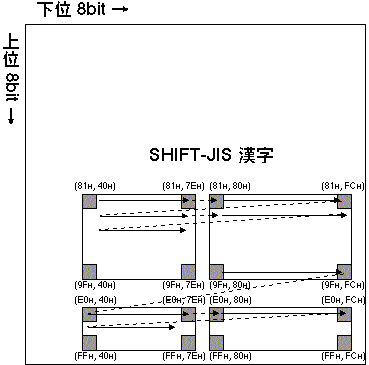
- JIS 漢字コード → SHIFT-JIS 漢字コード
- SHIFT-JIS 漢字コードは複雑で、ASCII コードの single-byte 文字にも
半角カナ文字にも割りあてられていない部分を縫うように利用して 漢字を割りあてている。
JIS は 1,2バイト目とも 0x21 〜 0x7E のコードを 使用していたが、SHIFT-JIS では 1バイト目の割りあてに
余裕が ないので、下の図でみるように漢字の割りあてられた部分が JIS にくらべて「横につぶれた」形になっている。
しかし割りあての 面積は同じであり、JIS が表現する漢字をすべて表現することができる。
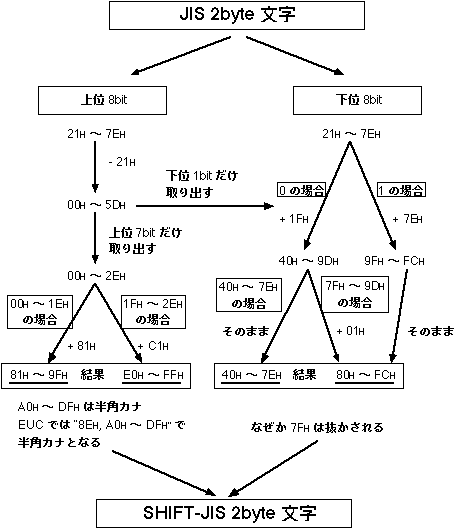
- このような複雑なコードに、JIS 漢字コードで 表現された文字を変換するアルゴリズムは、たとえば次のようになる。
Last modified: Wed Sep 26 18:39:22 2001
Yusuke Shinyama